今天刷视频的时候刷到了"低U高显"这个词说是
CPU对GPU性能产生限制的原因主要涉及计算资源、数据传输和任务调度等方面。以下是一些可能的原因:
- 数据传输瓶颈: GPU通常需要与CPU之间大量的数据传输,这包括将计算任务的输入数据传输到GPU,以及将计算结果传输回CPU。如果系统内存或PCIe总线的带宽有限,将会成为限制GPU性能的瓶颈。高效的数据传输是 GPU 计算效能的重要组成部分。
- 任务划分和调度: CPU负责管理整个系统的任务划分和调度,包括将计算任务分配给 GPU 处理。如果 CPU 在这个过程中效率低下,可能导致 GPU 无法充分利用其计算能力。尤其是在需要大规模并行计算的情况下,有效的任务划分和调度对于整体性能至关重要。
- CPU计算能力限制: 在某些情况下,CPU的计算能力可能成为限制因素。尽管 GPU 在并行计算方面表现优异,但某些任务可能需要在 CPU 上完成一部分计算,然后将中间结果传递给 GPU 进行进一步处理。如果 CPU 计算能力不足,这可能限制了整个计算过程的性能。
- 并发性和同步问题: 有些任务可能无法有效利用 GPU 的并行计算能力,因为它们可能涉及到需要在 CPU 和 GPU 之间进行频繁同步的操作。这种同步可能导致 CPU 等待 GPU 完成,从而减缓整个系统的速度。
- 系统架构和配置: 系统的整体架构和配置也可能对 CPU 和 GPU 的协同工作产生影响。例如,某些系统可能没有专门为 GPU 提供足够的 PCIe 带宽,或者可能存在其他硬件或软件层面的配置问题。
在实际应用中,通过优化数据传输、使用高效的并行编程模型、合理划分任务并使用专门设计用于并行处理的多核 CPU 等手段,可以缓解 CPU 对 GPU 性能的限制。然而,这需要系统设计者和开发人员仔细考虑整个系统的架构和配置。
作者:匿名用户 链接:https://www.zhihu.com/question/20978963/answer/17194080 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
速度区别主要是来自于架构上的区别。架构的不同则是因为硬件的设计目的不一样。
英伟达的CUDA文档里给了这样一幅图:
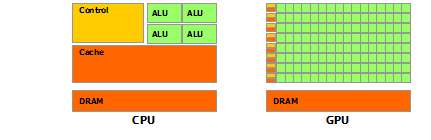
其中ALU就是“算术逻辑单元(
CPU和GPU进行计算的部分都是ALU,而如图所示,GPU绝大部分的芯片面积都是ALU,而且是超大阵列排布的ALU。这些ALU都是可以并行运行的,所以浮点计算速度就特别高了。
相比起来,CPU大多数面积都需要给控制单元和Cache,因为CPU要承担整个计算机的控制工作,没有GPU那么单纯。
所以GPU的程序控制能力相比CPU来说不强,稍早时候的CUDA程序像是递归都是不能用的(较新的设备上可以了)。
我觉得也不是CPU不能提高浮点计算速度,而是因为没什么特别的必要了。咱们通常的桌面应用根本没有什么特别的浮点计算能力要求。而同时GPU这样的设备已经出现了,那么需要浮点计算的场合利用上就行了